dev course - DE/TIL
[데브코스] TIL 41일차
nani-jin
2024. 5. 21. 17:25
데이터 인프라의 가장 기본적인 형태는 데이터 웨어하우스 + ETL 프로세스
1. 복습 및 개요
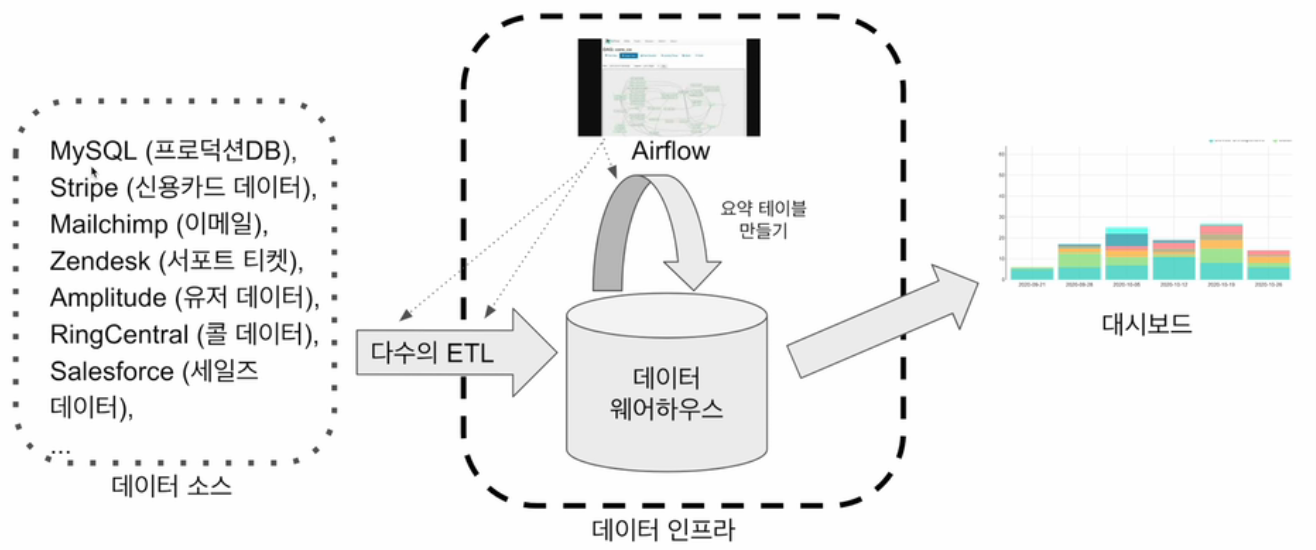
- 구성
- 데이터 소스, 데이터 인프라(다수의 ETL을 관리할 Airflow, 데이터 웨어하우스), 대시보드
- ETL(Extract, Transform, Load)
- Extract - 데이터 소스에서 데이터를 뽑아내는 것. 보통 API 호출
- Transform - 데이터 포맷을 바꾸는 것
- Load - 데이터 웨어하우스에 테이블 형태로 적재
- ETL vs. ELT
- ETL은 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스라면, ELT는 데잍 웨어하우스 내부 데이터를 조작해 (보통은 좀 더 추상화되고 요약된) 새로운 데이터를 만드는 프로세스
- 데이터 엔지니어들이 자신이 가져온 raw 데이터가 어떻게 쓰이는지 모르는 문제가 발생할 때가 있음
- Data Lake vs. Data Warehouse
- 데이터 레이크는 구조화 데이터 + 비구조화 데이터가 저장되며, 보존 기한이 없는 모든 데이터를 원래 형태대로 저장하기 때문에 스토리지에 가까움. 보통 데이터 웨어하우스보다 몇배는 더 큼
- 데이터 웨어하우스는 보존 기한이 있는 구조화된 데이터를 저장하고 처리하는 스토리지로, 보통 BI 툴들(looker, tableau, superset, ...)은 데이터 웨어하우스를 백엔드로 사용함

2. 데이터 파이프라인 - 개요
- 데이터를 소스로부터 목적지로 복사하는 작업
- 데이터 소스 예시
- Click stream, call data, ads performance data, transactions, sensor data, metadata, ...
- More concrete examples : production databases, log files, API, stream data (Kafka topic)
- 데이터 목적지 예시
- 데이터 웨어하우스, 캐시 시스템(Redis, Memcache), 프로덕션 DB, NoSQL, S3, ...
- 데이터 소스 예시
- 종류
- Raw data ETL jobs
- 외부(회사 외부)와 내부(회사 내부) 데이터 소스에서 데이터를 읽어다가 - 많은 경우 API를 통해 이뤄짐
- 적당한 데이터 포맷 변환 후, - 데이터 크기가 커지면 Spark 등이 필요해짐
- 데이터 웨어하우스에 로드
- Summary/Report jobs
- DW 혹은 DL로부터 데이터를 읽어 다시 DW에 쓰는 ETL
- Raw data를 읽어서, 일종의 Summary/Report 형태의 테이블을 다시 만드는 용도
- Summary 테이블은 SQL 만으로 만들고, 이는 분석가가 하는 것이 맞음
- 특수한 형태로는 A/B 테스트 결과를 분석하는 데이터 파이프라인도 존재함
- 데이터 엔지니어는 데이터 분석가들이 편하게 할 수 있는 환경을 만들어 주는 것이 관건!
- Production Data jobs
- DW로부터 데이터를 읽고, 다른 스토리지(많은 경우 프로덕션 환경)로 쓰는 ETL
- Summary 정보가 프로덕션 환경에서 성능 이슈로 필요한 경우
- 머신러닝 모델에 필요한 feature들을 미리 계산해두는 경우
- 목적지 - NoSQL, OLTP, Redis/Memcache, ElasticSearch ... 등
- DW로부터 데이터를 읽고, 다른 스토리지(많은 경우 프로덕션 환경)로 쓰는 ETL
- Raw data ETL jobs
- Production Data jobs 예시
- 프로덕션 DB 성능 상의 이슈로 백엔드/프론트엔드 엔지니어들이 직접 계산하지 않고, 데이터 웨어하우스에 있는 데이터를 읽어다가 사용


3. 데이터 파이프라인 - 고려할 점
- 이상과 현실 간의 괴리
- 이상 혹은 환상
- 내가 만든 데이터 파이프라인은 문제 없이 동작할 것
- 내가 만든 데이터 파이프라인을 관리하는 것은 어렵지 않을 것
- 현실 혹은 실상
- 버그
- 데이터 소스상의 이슈 : What if data sources are not available or change its data format
- 데이터 파이프라인들간의 의존도에 대한 이해도 부족
- 데이터 파이프라인의 수가 늘어나면 유지보수 비용이 기하급수적으로 늘어남
- 데이터 소스 간의 의존도로 인한 복잡성
- 더 많은 테이블들에 대한 관리 필요성
- 이상 혹은 환상
- 좋은 실례들(Best Practices)
- 데이터가 작을 경우, 가능하면 매번 통째로 복사해 테이블 만들기(Full Refresh)
- 과거 데이터가 문제가 있을 경우, 매번 다시 만들기 때문에 문제 해결
- 데이터가 커지면 불가능함
- 데이터가 클 경우, Incremental update. 이를 위한 조건이 있음
- 데이터 소스가 프로덕션 DB 테이블이라면, 다음 필드 필요
- created(데이터 업데이트 시에는 필요하지 않음), modified, deleted
- 데이터 소스가 API라면, 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야함
- 데이터 소스가 프로덕션 DB 테이블이라면, 다음 필드 필요
- 멱등성(Idempotency)을 보장하는 것이 중요
- 데이터 소스가 변하지 않았다는 가정 하에, 파이프라인을 1번 실행했을 때와 100번 실행했을때 최종 테이블 내용이 달라지지 않아야함
- 특히, 중복 데이터가 생기지 않아야함
- critical point들이 모두 one atomic action으로 실행되어야 함(다같이 성공하거나 다같이 실패하거나)
- 데이터베이스 복구
- 실패한 데이터 파이프라인에 대한 재실행이 용이해야함
- 과거 데이터를 다시 채우는 과정 또한 용이해야함
- Airflow는 특히 backfill에 강점을 가지고 있음
- 데이터 파이프라인의 입/출력을 명확히하고 문서화
- 각 파이프라인에 대한 설명을 명시
- 파이프라인에 대한 오너를 명시(technical owner, business owner)
- 이 정보는 나중에 데이터 카탈로그로 들어가, 데이터 디스커버리에 사용됨
- 데이터 리니지가 중요해지며, 이걸 이해하지 못하면 온갖 종류의 사고가 발생됨
- 주기적으로 쓸모 없는 데이터들을 삭제
- 데이터 파이프라인 사고시, 사고 리포트(post-mortem) 쓰기
- 동일한 혹은 비슷한 사고 예방
- 사고 원인을 이해하고 이를 방지하기 위한 액션 아이템들을 실행하기 위함
- 기술 부채의 정도를 이야기해주는 바로미터
- 중요 데이터 파이프라인의 입/출력 체크
- 아주 간단하게는 입력 레코드 수, 출력 레코드 수 체크
- Summary 테이블을 만들어내고, PK의 primary key uniqueness가 보장되는지 체크
- 중복 레코드 체크
- 데이터가 작을 경우, 가능하면 매번 통째로 복사해 테이블 만들기(Full Refresh)
4. 간단한 ETL 작성 실습
- 사용할 데이터 소스
- https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv
- name, gender 두 개의 필드 존재
- 사용할 데이터 웨어하우스
- Redshift dc2.large
- 2 CPU, 15GB memory, 160GB SSD
- Host : learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com
- Port : 5439
- Database : dev
- ID : 본인 아이디. 이 아이디로 스키마가 만들어져 있음
- Password : 본인 패스워드
- Redshift dc2.large
- 실습 개요
- Redshift에 테이블 생성
- extract, transform, load 세 개의 함수를 작성
- 웹상에 존재하는 CSV 파일 → Redshift에 있는 테이블로 복사
- 트랜잭션
- 중간에 실패하면 불완전 상황에 놓이는 작업들이 있다면?
- 그 작업들을 묶어 하나라도 실패하면 모두 실패. 모두 성공해야 성공
- BEGIN ~ COMMIT. ROLLBACK
- 보통 python의 try, except와 같이 사용
# 다음에 유의!
try:
cur.execute(create_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise # 꼭 해줘야함. 아니면 에러발생 여부를 모름!
5. Airflow
- 파이썬으로 작성된 데이터 파이프라인(ETL) 프레임워크
- Airbnb에서 시작한 아파치 오픈소스 프로젝트로, 가장 많이 사용됨
- 특징
- 데이터 파이프라인 스케줄링 지원 - 정해진 시간에 ETL 실행 또는 한 ETL 실행이 끝낳을때 다음 ETL 실행을 지원함
- web UI 제공
- 데이터 파이프라인(ETL)을 쉽게 만들 수 있도록 해줌(참고: https://airflow.apache.org/docs/)
- Airflow에서는 데이터 파이프라인을 DAG(Directed Acyclic Graph)라고 부름. 하나의 DAG는 하나 이상의 태스크로 구성됨
- '20년 12월에 Airflow 2.0이 릴리즈됨
- Airflow 버전 선택 방법 : 큰 회사에서 사용하는 버전이 무엇인지 확인해 버전 안전성을 확인함(참고: https://cloud.google.com/composer/docs/concepts/versioning/composer-versions)
- DAG(Directed Acyclic Graph)
- Airflow에서 ETL을 부르는 명칭으로, 태스크로 구성됨
- 태스크 - Airflow의 오퍼레이터(Operator)로 만들어짐
- 다양한 종류의 오퍼레이터를 제공하고 있으며, 경우에 맞게 사용 오퍼레이터를 결정하거나 직접 개발할 수 있음
- (예시) 3개의 태스크로 구성된다면 Extract, Transform, Load로 구성
- Airflow에서 ETL을 부르는 명칭으로, 태스크로 구성됨


- 구성
- web server
- scheduler
- DAG들을 worker들에게 배정하는 역할 수행
- worker
- 실제 DAG를 실행하는 역할 수행
- 메타 데이터 데이터베이스
- scheduler와 각 DAG의 실행 결과가 저장되는 별도의 데이터베이스
- 기본적으로 Sqlite이 설치되나, 별도로 MySQL이나 PostgreSQL을 설치해 사용하는 것이 일반적
- queue(다수서버 구성인 경우에만)
- 이 경우, Executor가 달라짐
- Airflow 스케일링 방법
- Scale up - 더 좋은 사양의 서버 사용
- Scle out - 서버 추가
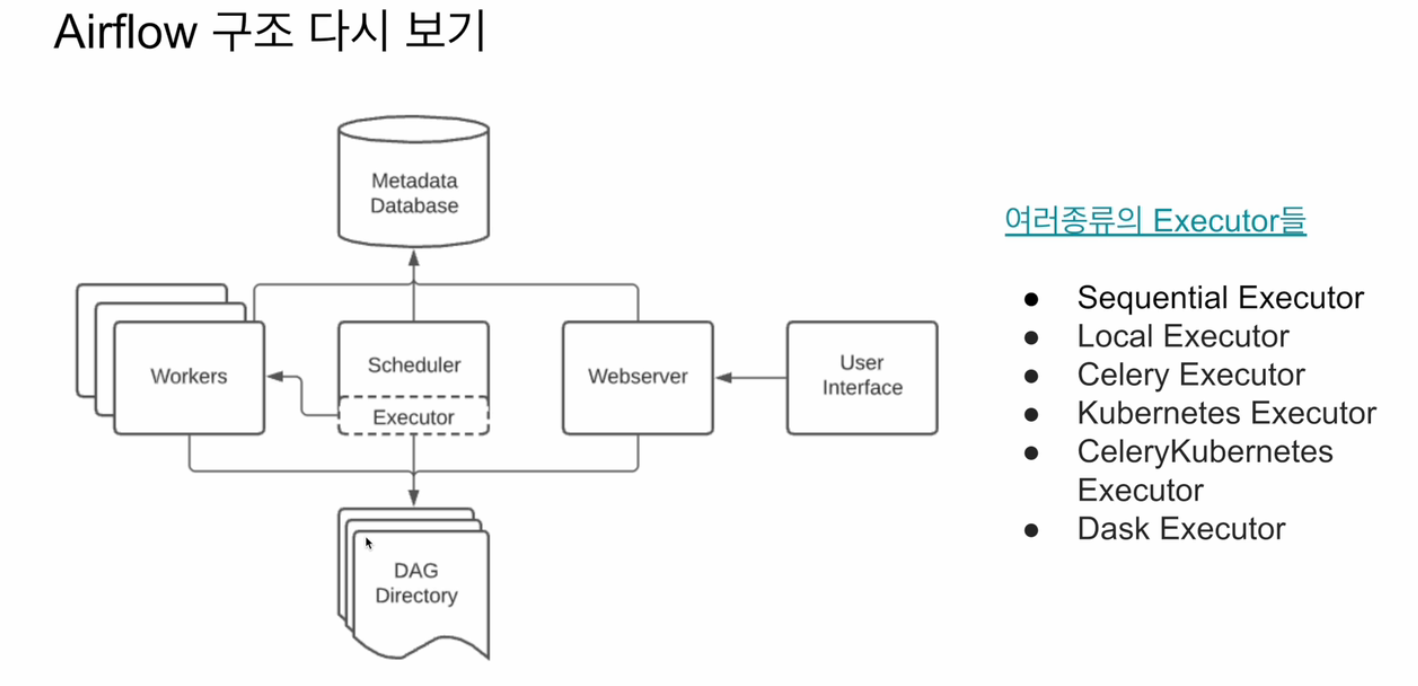
- 장점
- 데이터 파이프라인을 세밀하게 제어 가능
- 다양한 데이터 소스와 데이터 웨어하우스 지원
- Backfill이 용이함
- 단점
- 배우기 쉽지 않음
- 상대적으로 개발 환경을 구성하기 쉽지 않음
- 직접적으로 운영하는 것이 쉽지 않음. 클라우드 버전 사용이 선호됨
- GCP - "Cloud Composer"
- AWS - "Managed Workflows for Apache Airflow"
- Azure - "Data Factory Managed Airflow"
- 결국 Airflow 코딩 = DAG를 만들고, DAG에 대한 정보(스케줄링 등)를 지정하고 DAG를 구성하는 다양한 태스크들을 오퍼레이터로 구현하는 것