Airflow의 목표를 생각해보면, DAG의 기본 구조에 대해 잘 이해할 수 있다.
[목표] 복잡한 데이터 파이프라인을 쉽게 정의하고, 일정에 맞춰 실행하며, 문제 발생 시 신속하게 대응할 수 있는 환경을 제공하는 것!
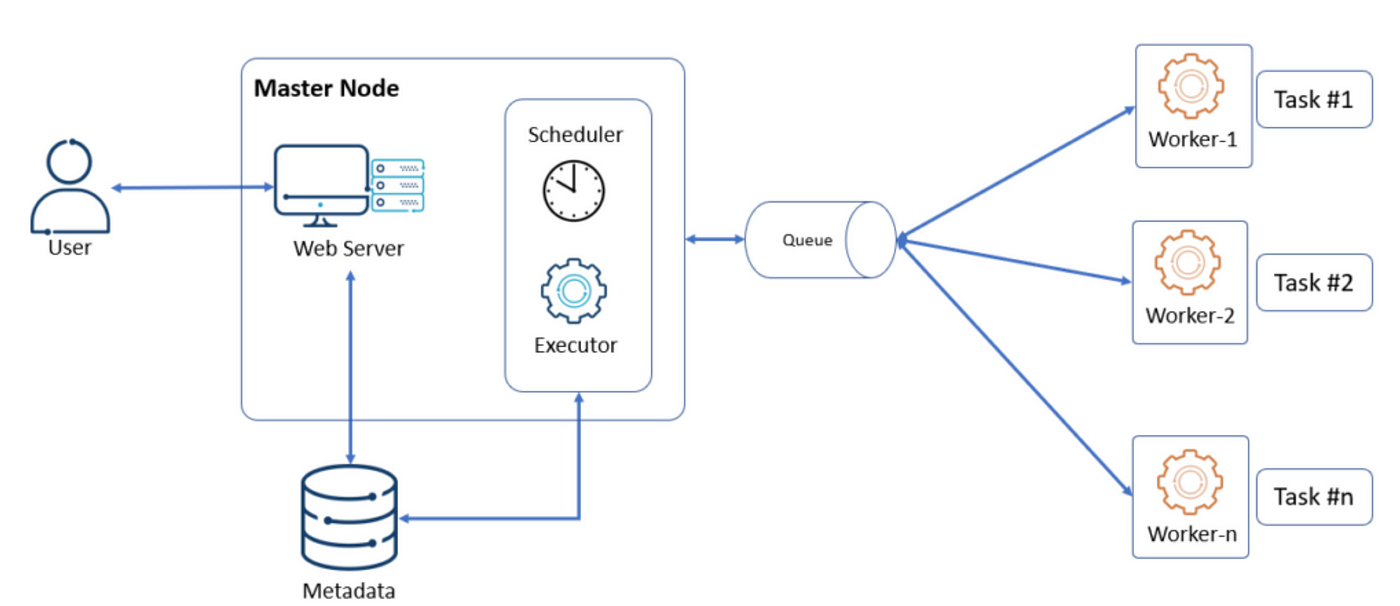
1. DAG를 대표하는 객체를 먼저 만듦
- 이름, 실행 주기, 실행 날짜, 오너 등으로 이루어짐
- DAG. Directed Acyclic Graph는 순회하지 않고 한 방향으로 흐르는 그래프를 뜻하는데, 이는 ETL workflow의 구조와 실행 방식이 DAG의 개념과 맞아 떨어지기 때문에 Airflow에서는 이를 DAG라고 부름
2. DAG를 구성하는 태스크들을 만듦
- 순서
- 태스크 별로 작업 유형을 파악하고 적절한 오퍼레이터를 선택함
- 태스크 ID를 부여하고, 해야할 작업의 세부 사항을 지정
*모든 DAG가 스케줄을 가져야하는 것은 아님!
- 주의할 점
- 태스크를 과도하게 늘린다면, 전체 DAG 실행 시간이 늘어나고 스케줄러에 부하가 생김
- 태스크를 과도하게 줄인다면, 모듈화가 안되고 실패시 재실행이 오래걸림
- 밸런스 있게 조절할 것. 어떻게? 실패시 재실행되는 시간의 관점에서 태스크를 나누면 좋음
+) 태스크를 적당하게 구성하다는건?
- 예를 들어, 다음과 같은 코드는 태스크가 api call → list에 보관 → redshift connection → create table → insert into 로 이루어져 있는데 이는 하나의 태스크에서 모든 과정을 처리하는 예시로 redshift connection 하나만 실패해도 api call부터 다시 시작해야하는 비효율성을 불러 일으킴
from airflow import DAG
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.decorators import task
from datetime import datetime
from datetime import timedelta
import requests
import logging
import json
def get_Redshift_connction():
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
return hook.get_conn().cursor()
@task
def etl(schema, table):
api_key = Variable.get("open_weather_api_key")
# 서울 위도, 경도
lat = 37.5665
lon = 126.9780
# 1. api call
url = f"https://api.openweathermap.org/data/2.5/onecall?lat={lat}&lon={lon}&appid={api_key}&units=metric&exclude=current,minutely,hourly,alerts"
response = requests.get(url)
data = json.loads(response.text)
# 2. list에 보관
ret = []
for d in data["daily"]:
dat = datetime.fromtimestamp(d["dt"]).strftime('%Y-%m-%d')
ret.append("('{}',{},{},{})".format(day,d["temp"]["day"], d["temp"]["min"], d["temp"]["max"]))
# 3. redshift connection
cur = get_Redshift_conneciton()
# 4. CREATE TABLE
drop_recreate_sql = f"""DROP TABLE IF EXISTS {schema}.{table};
CREATE TABLE {schema}.{table} (
date date,
temp float,
min_temp float,
max_temp float,
created_date timestamp default GETDATE()
);
"""
# 5. INSERT INTO
insert_sql = f"""INSERT INTO {schema}.{table} VALUES """ + ",".join(ret)
logging.info(drop_recreate_sql)
logging.info(insert_sql)
try:
cur.execute(drop_recreate_sql)
cur.execute(insert_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
with DAG(
dag_id = 'Weather_to_Redshift',
start_date = datetime(2023,5,30), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
) as dag:
etl("kcmclub22", "weather_forecast")- 이를 task1(api call → list에 보관), task2(redshift connection → create table → insert into)로 쪼갠다면, redshift connection을 실패해도 api call로 가져온 데이터가 리스트로 보관되는 것은 완료되었기 때문에 다시 가져오지 않아도됨 → 효율성 증대!
from airflow import DAG
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.decorators import task
from datetime import datetime
from datetime import timedelta
import requests
import logging
import json
def get_Redshift_connction():
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
return hook.get_conn().cursor()
@task
def extract():
api_key = Variable.get("open_weather_api_key")
# 서울 위도, 경도
lat = 37.5665
lon = 126.9780
# 1. api call
url = f"https://api.openweathermap.org/data/2.5/onecall?lat={lat}&lon={lon}&appid={api_key}&units=metric&exclude=current,minutely,hourly,alerts"
response = requests.get(url)
data = json.loads(response.text)
# 2. list에 보관
ret = []
for d in data["daily"]:
dat = datetime.fromtimestamp(d["dt"]).strftime('%Y-%m-%d')
ret.append("('{}',{},{},{})".format(day,d["temp"]["day"], d["temp"]["min"], d["temp"]["max"]))
return ret
@task
def tl(schema, table, records):
# 3. redshift connection
cur = get_Redshift_conneciton()
# 4. CREATE TABLE
drop_recreate_sql = f"""DROP TABLE IF EXISTS {schema}.{table};
CREATE TABLE {schema}.{table} (
date date,
temp float,
min_temp float,
max_temp float,
created_date timestamp default GETDATE()
);
"""
# 5. INSERT INTO
insert_sql = f"""INSERT INTO {schema}.{table} VALUES """ + ",".join(ret)
logging.info(drop_recreate_sql)
logging.info(insert_sql)
try:
cur.execute(drop_recreate_sql)
cur.execute(insert_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
with DAG(
dag_id = 'Weather_to_Redshift',
start_date = datetime(2023,5,30), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
) as dag:
lines = extract()
tl("kcmclub22", "weather_forecast", lines)
3. 태스크 간의 실행 순서 결정
# Python Operator
task1 >> task2
# Task Decorator
with DAG(...
}
) as dag:
lines = extract()
tl("kcmclub22", "weather_forecast", lines)
[출처] 데이터 엔지니어링 데브코스
'data engineering > airflow' 카테고리의 다른 글
| [Airflow] 로그 파일 관리 (0) | 2024.06.17 |
|---|---|
| [Airflow] Python Operator과 Task Decorator (1) | 2024.06.04 |
| [Airflow] Airflow는 왜 등장했을까? + 구성 요소 (0) | 2024.06.03 |


