https://nani-log.tistory.com/159?category=720053
Hadoop Ecosystem -2 (Mapreduce2, YARN)
https://nani-log.tistory.com/158 Hadoop Ecosystem -1 (HDFS, MapReduce1)데이터 웨어하우스를 공부하다보니, 분산시스템의 근간인 하둡 에코시스템을 대체해 사용자가 관리하는 부분을 데이터 웨어하우스가 대
nani-log.tistory.com

앞선 1,2 포스트에서는 하둡을 개발하게 된 계기와 함께 hdfs, mapreduce, yarn을 살펴봤다. 이번 포스트에서는 하둡의 사용성을 높이기 위한 노력 중 하나였던 Hive에 대해 알아보고자 한다
mapreduce의 코드를 본 적이 있다면 알겠지만, 개발자가 아닌 데이터 분석가나 비개발자들이 작성하기엔 복잡하고 어렵다는 단점이 있었다. 개발자들은 이런 불편한 부분을 해소하고 싶었고, 이를 구현한 것이 Hive다
Hive는 mapreduce 코드를 직접 구성하지 않고 친숙한 SQL을 기반으로 만들어진 HiveQL 쿼리를 통해 데이터를 처리할 수 있다. Hive와 Hive metastore를 설치하면, 사용자는 HiveQL 쿼리를 통해 테이블을 만들수 있고, 메타스토어에 테이블에 대한 스키마 정보를 유지한다
Hive
Hive를 구성하고 있는 요소들을 살펴보면 다음과 같다
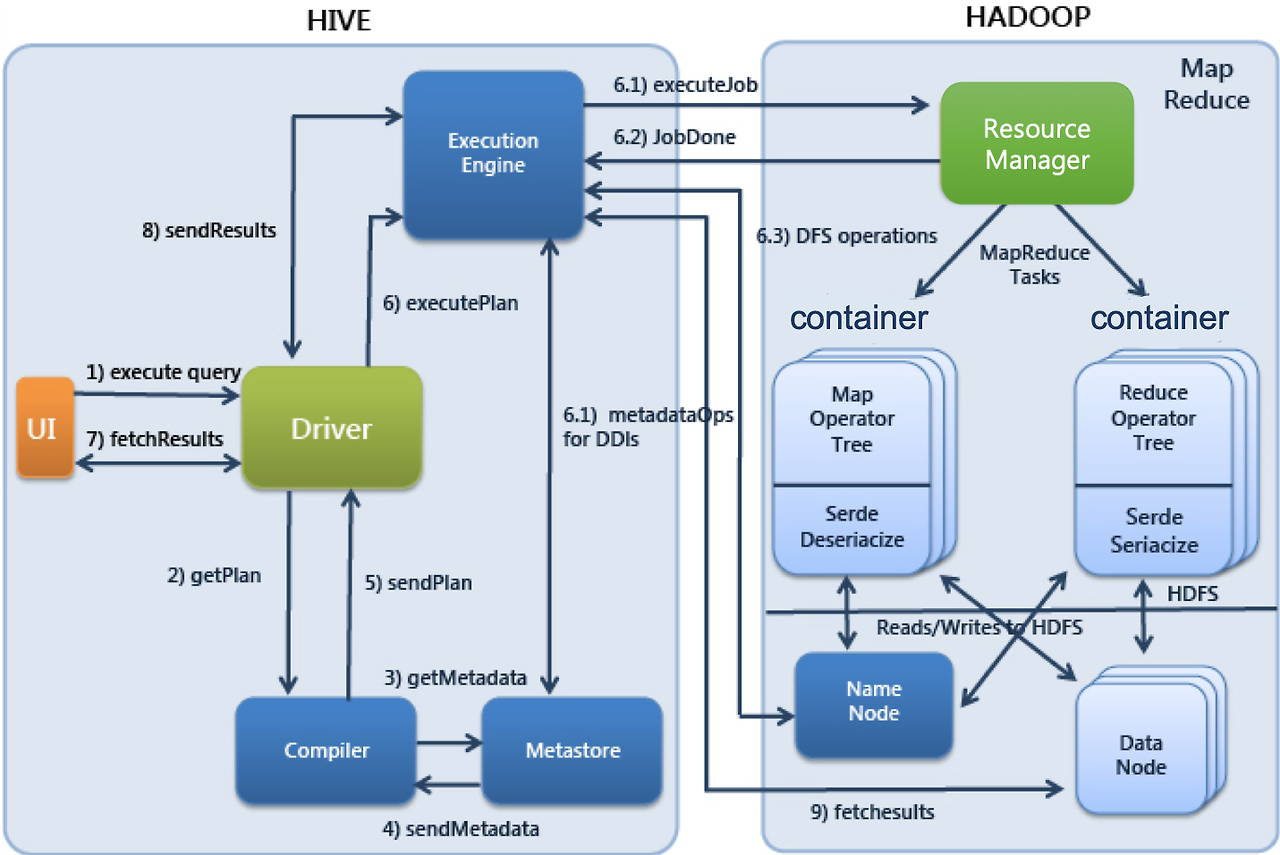
- HiveQL(Hive Query Language)
- SQL를 기반한 언어로, Hive에서 쿼리를 수행하는데 사용된다
- 이를 통해 복잡한 Mapreduce 작업을 추상화하고, SQL을 통해 쉽게 데이터를 처리할 수 있게 해준다
- Hive Metastore
- 테이블 구조, 스키마, 파티션 등의 정보를 저장한다
- 메타스토어는 관계형 데이터베이스에서 운영되고 HiveQL 쿼리가 실행될 때 참조된다. 이를 통해 데이터의 물리적 위치와 구조를 쉽게 추적하고 쿼리할 수 있다
- Driver
- HiveQL 쿼리를 입력받고, 이를 Mapreduce 작업으로 변환해 하둡에서 동작할 수 있도록 해준다
- 컴파일러가 생성한 논리적 계획을 구체적인 실행 계획으로 변환해 Execution Engine에게 전달한다
- Compiler
- 드라이버를 통해 쿼리를 컴파일하고, 논리적 계획을 생성해 드라이버에게 전달한다
- Execution Engine
- 하둡의 Mapreduce를 실행 엔진으로 사용한다
- Mapreduece는 드라이버에게 전달 받은 실행 계획을 실제로 수행한다
사용자가 HiveQL로 쿼리를 작성해 전달하면, 컴파일러는 쿼리를 받아 논리적 실행 계획을 생성하고, Driver는 이를 Mapreduce 작업으로 변환해 실행 엔진인 Mapreduce에게 전달한다. Mapreduce는 Map/Reduce로 단계를 나누어 데이터를 처리하고 완료된 결과를 전달하면 UI를 통해 결과를 조회할 수 있다
Mapreduce의 비효율성
하지만 Mapreduce를 실행 엔진으로 사용하기 때문에 여러 비효율적인 문제가 대두됐다
첫번째로는 각 단계(Map, Reduce)가 끝날 때마다 중간 결과가 디스크에 저장되어 속도가 느렸다. 또한 잡의 결과를 HDFS에 저장해 복제 오버헤드가 존재했다
두번째로는 배치 처리를 위해 설계되었기 때문에 실시간 분석이 필요한 환경과는 적합하지 않았다. 데이터를 분석할 때 배치만이 아닌 실시간으로 분석을 원하는 사용자들은 이를 해소할 수 없었다
사람들은 더 유연성 있고 실시간 분석 쿼리를 처리하기를 원했고 이에 Tez, Spark 같은 실행 엔진을 도입하기 시작했다
SQL on Hadoop
더 나아가 실행 엔진만 대체하는게 아니라 Hive를 대체할 독립적인 쿼리 엔진이 개발되었다. 그 엔진들이 Impala, Trino다. Impala와 Trino는 자체 SQL 인터페이스를 사용하고 메모리 기반으로 데이터를 처리해 실시간 쿼리 성능이 뛰어나다
Hive와 유사하게 HDFS 같은 분산 파일 시스템에서 동작하지만, 독립적인 쿼리 엔진으로 Hive를 대체할 수 있다
정리
Hive는 mapreduce의 사용성을 높이기 위해 등장했지만 더 주가 되어 Impala, Trino와 같은 또다른 프레임워크가 개발되는 흐름을 만들어줬다. 단한번에 완벽한 프레임워크를 완성하는게 아니라, 지금 처한 문제를 어떻게 해결할지에 대해 중점을 두면 더 좋은 도구를 개발할 수 있는 지름길이 되는 것 같단 생각이 든다
Hive의 여러 기능이나 특성에 대해선 다른 포스트에서 좀 더 깊이 있게 다뤄봐야겠다
'data engineering > hadoop' 카테고리의 다른 글
| Apache Hive -1 (핵심 구성 요소와 개념) (3) | 2024.09.26 |
|---|---|
| Hadoop Ecosystem 쓱 보기 -4 (Hive의 대안. Impala) (0) | 2024.09.26 |
| Hadoop Ecosystem 쓱 보기 -2 (Mapreduce2, YARN) (0) | 2024.09.23 |
| Hadoop Ecosystem 쓱 보기 -1 (HDFS, MapReduce1) (2) | 2024.09.21 |



