스파크(Spark)는 맵리듀스(Mapreduce)를 대체하는 강력한 분산 데이터 처리 시스템이다. 맵리듀스는 map → shuffle → reduce의 중간 결과를 디스크에 써 디스크 I/O와 네트워크 오버헤드가 매번 발생했는데, 스파크는 중간 결과를 메모리에 써 최소 10배 ~ 최대 100배의 성능 개선을 이뤄냈다. 뿐만 아니라 map, reduce라는 정해진 틀에서 벗어나 다양한 데이터 처리 연산(filter, join, groupBy, ...)을 지원해 유연하고 더 직관적인 처리를 지원한다
스파크 구성 요소
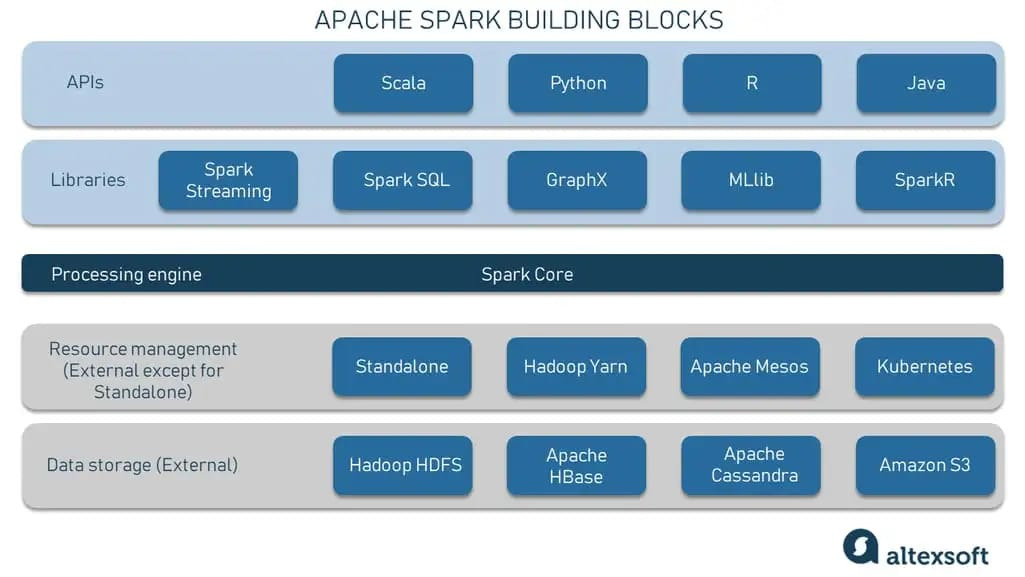
1) 분산 스토리지
앞서 스파크는 분산 데이터 처리 시스템이라고 언급했다. 이는 한 대의 서버가 처리할 수 없는 양의 데이터를 처리하기 때문에 여러 대의 서버로 구성된 클러스터 위에서 동작한다는 의미다. 데이터 처리를 위해선 데이터가 분산 저장되어 있어야 하는데, 이를 위해 분산 스토리지를 사용한다
2) 리소스 매니저
스파크는 여러 대의 서버로 구성된 클러스터 위에서 동작하기에, 이 클러스터를 관리하고 스케줄링할 수 있는 주체가 필요하다. 하둡 에코 시스템에서는 YARN, 하둡이 아닌 다른 환경에서도 자유롭게 사용할 수 있는 Mesos, 최근 많이 사용되는 컨테이너 기반의 매니저인 Kubernetes를 통해 스파크로 제출된 잡에 대한 리소스 매니징과 스케줄링이 가능하다
3) 스파크 코어
스파크 코어는 스파크의 중신이 되는 분산 데이터 처리 엔진이다. RDD(사용자가 요청한 데이터를 분산된 형태로 메모리에 올리는 데이터 구조)로 데이터를 추상화하고, 지연 평가를 통해 액션 연산이 호출될 때까지 기다리며 여러 변환 작업을 최적화한다. RDD는 내결함성과 병렬 처리를 지원해 대규모 데이터 처리를 효율적으로 수행한다. 이 부분에 대해서는 추후 포스트에서 다룰 예정이다
4) 라이브러리 & API
그 위에 보이는 라이브러리는 스파크에서 제공하는 다양한 처리 프레임워크다. 스파크는 마치 종합 선물세트 같이 배치 처리뿐만 아니라 스트리밍, SQL, ML 등을 지원해 사용자가 스파크를 통해 확장성 있게 데이터를 활용할 수 있도록 도와준다. 또한 Scala 뿐만 아니라 Python, R, Java 언어에 대해 지원해 프로그래밍 할 수 있다
스파크 아키텍처

스파크는 크게 마스터 - 워커 형태의 아키텍처로 구성된다. 사용자가 상호작용하는 드라이버(Driver)가 있는 마스터 노드와 클러스터 매니저를 통해 실질적인 작업을 수행하는 워커 노드(Worker Node)로 구성되어 있다. 드라이버는 작업을 조정하고 명령을 내리며, 워커 노드는 주어진 작업을 분산 처리하여 결과를 산출한다
워커 노드는 각자 분산된 데이터를 처리하기 위해 캐싱하고 실제 태스크를 실행하는데, 특히 반복 처리적인 연산에서 디스크에 결과를 쓰지 않고 캐싱된 데이터를 활용하기 때문에 성능이 높다. 워커 노드를 태스크를 병렬 처리로 실행하고, 그 결과를 마스터 노드에 반환한다
정리
스파크는 분산! 데이터 처리! 시스템이다. 분산 시스템에 대해 더 공부할수록 실제로 개발하고 오픈한 개발자들이 새삼 대단하게 느껴진다... 다음 포스트에서는 스파크의 핵심인 RDD와 그 내부 동작에 대해 자세히 알아보려한다
'data engineering > spark' 카테고리의 다른 글
| 더미데이터 생성기 (3) | 2024.10.16 |
|---|---|
| Apche Spark intro -3 (RDD, DataFrame, Dataset) (5) | 2024.10.16 |
| Apache Spark intro -2 (RDD. Resilient Distributed Dataset) (4) | 2024.10.15 |


